
Z wikipedii: http://pl.wikipedia.org/wiki/Porz%C4%85dek_leksykograficzny
| Porządek leksykograficzny – pojęcie matematyczne odnoszące się do sposobu uporządkowania elementów zbiorów. |
Dzisiaj krótko o dość często zapominanym szczególe, który może znacząco wpłynąć na wyniki Waszych zapytań.
W wielu systemach można napotkać na ciekawe przypadki trzymania liczb w polach (n)char,(n)varchar.
Zapewne każdy z nich dałoby się jakoś usprawiedliwić.
Najczęściej jest to wynik decyzji o „uniwersalności” kolumny – pierwotnie zakładano trzymanie napisów, a że wybrano za identyfikator/klucz zwykłą liczbę to od momentu zdrożenia w takiej kolumnie znajdują się same liczby. Oczywiście jest to marnotrawstwo miejsca i obniżanie wydajności bazy. Wystarczy sobie wyobrazić, że dowolna liczba z zakresu od -2,147,483,648 do 2,147,483,647 da się przetrzymać w 4 bajtach (int). Taka sama liczba (np ta dodatnia) zapisana jako napis (varchar) zajmie 10 znaków a więc 10 bajtów + 2 bajty, które varchar rezerwuje na określenie długości napisu. Co gorsza, jeśli ta liczba będzie trzymana w polu nvarchar to wszystko będzie ważyc dwa razy więcej (nvarchar to unicode, tam na każdy znak przypadają 2 bajty)
Jednak z takiego przechowywania liczb wynika jeszcze jeden, bardzo poważny problem. Każdy z nas jak widzi cyfry i liczby to nie zastanawia się co to jest. Poważnie, bardzo łatwo jest nie zauważyć jakiego typu są dane które widzimy.
Dla nas naturalnym jest, że po 1 jest 2,
a 2 jest mniejsze od 100. A co na to SQL?
DECLARE @t TABLE ( i VARCHAR(100) )
INSERT INTO @t
VALUES ( 1 ),
( 2 ),
( 100 )
SELECT *
FROM @t
ORDER BY i
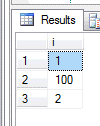
A co jeżeli trzymać będziemy kwoty w polu z napisem i będziemy chcieli wybrać największą wartość?
DECLARE @t TABLE ( i VARCHAR(100) ) INSERT INTO @t VALUES ( 1.99 ), ( 2.12 ), ( 100.90 ) SELECT MAX(i) FROM @t
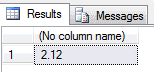
Teraz mam nadzieję widać jak ważna jest typizacja i techniczna wiedza o danych (nie tylko biznesowa). Sposób sortowania zarówno liczb jak i liter w postaci jednego napisu znane jest jako sortowanie naturalne. Trzeba więc pamiętać o takich detalach!
{kind=link}