
Microsoft kontynuuje swoją nową strategię. Ostatnie zmiany związane z jego dołączeniem do Linux Foundation wszystkich zaskoczyły.. SQL Server dla Linuxa również. Ale to co ogłosił 16 listopada zasługuje na większą czcionkę:
WSZYSTKIE EDYCJE SQL SERVER 2016 SP1: STANDARD, WEB, EXPRESS A NAWET LOCALDB DOSTAJĄ FUNKCJONALNOŚCI WERSJI ENTERPRISE! ZA DARMO, DLA WSZYSTKICH!
Wpis na blogu msdn „SQL Server Release Services” zawiera poniższe zestawienie ficzerów:
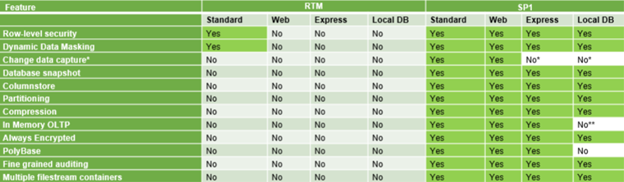
I oto właśnie wszyscy kupujący SQLe ENT dla powyższych funkcjonalności przecierają oczy ze zdumienia: „ALE JAK TO?!”
Ano tak to! Główna idea, która przyświeca nowym zmianom to możliwość developmentu wszystkich rozwiązań programistycznych bez uzależniania się od wersji silnika bazy. Po co więc wersja Enterprise? SKALOWALNOŚĆ! Koniec ze sztucznym ograniczaniem możliwości. Korzystasz z wszystkich funkcji na środowiskach skrojonych na miarę Twoich potrzeb. Potrzebujesz więcej core’ów niż 24? Więcej RAMu niż 128GB? Clustering HA/AlwaysON? Kup enterprise. Ale jeśli nie potrzebujesz dużego serwera, ale chcesz partycjonować tabele? Tworzyć snapshoty? Korzystać z In Memory OLTP? PROSZĘ! Możesz to zrobić nawet w darmowym Express. Nie wiem tylko jeszcze czy MSSQL@Linux również dostanie wszystkie wodotryski, oczywiście interpretując doniesienia wyczytane w różnych miejscach – tak, dostanie. O ile będzie to fizycznie możliwe (czyt. silnik pozwoli na implementację).
GDZIE JEST HACZYK?
Moim zdaniem nie ma żadnego, oczywiście z wyjątkiem obowiązkowego zmigrowania do najnowszej wersji. Microsoft wykorzystuje „nowy” trend, który już dawno temu sprawdził się choćby w technologiach Open Source. Swobodny dostęp do rozwiązań, z których więcej osób może korzystać powinien pozytywnie wpłynąć na sprzedaż ich produktów. Czy ta koncepcja się sprawdzi? Czas pokaże. To trochę tak jak z teorią o obniżaniu podatków i wzroście gospodarczym 🙂
Update1:
A jednak są pewne limity:
- w przypadku columnstore index część internalowych tricków wydajnościowych jest ograniczona. Przykładowo zrównoleglenie (degree of parallelism) ograniczone jest do dwóch wątków na Standard i jednego w Express. Jest tego jednak więcej. Szczegóły opisane dość dobrze TUTAJ,
- natomiast In-Memory OLTP ma ograniczenia na pamięć 🙁 Express tylko 352MB, Web 16GB, Standard 32GB. Szczegóły TUTAJ.
TO NIE WSZYSTKO!
SP1 to również kilka innych kluczowych zmian. Do najważniejszych zaliczam:
- klonowanie baz poleceniem DBCC CLONEDATABASE . Teraz możemy jednym poleceniem wykonać klon bazy bez danych, zachowując jej schemat. Można opcjonalnie pominąć querystore i/lub statystyki przy wykonywaniu tej operacji. Szczegóły tutaj: KB3177838,
- polecenie CREATE OR ALTER . Lata oczekiwań, jęczenia developerów i żmudnego implementowania IF EXISTS. NARESZCIEEEE!!!!,
- logowanie różnic w wielkościach pików tempdb w logu bazy. Dzięki temu łatwiej zauważyć różnice, które nie pozwolą nam skorzystać z tricków wydajnościowych przy zrównoleglaniu operacji dyskowych do plików tempdb,
- sys.dm_exec_query_statistics_xml. Nowy DMF do przeglądania planów uruchomionych zapytań z UWAGA – aktualną ilością wierszy,
- obsługa DROP TABLE w replikacji. Uwierzcie mi, uruchamianie skryptów deploymentowych na bazach z włączoną replikacją to prawdziwa sztuka! Od teraz żadnego rzeźbienia w publikacjach (tak potocznie nazywa się zestaw tabel do replikacji).
Reszta ciekawych zmian opisana jest tutaj.
Czuję się jak w Matrixie. To co się dzieje teraz, do niedawna było nie do pomyślenia.. JESTEM POD OGROMNYM WRAŻENIEM. Z punktu widzenia admin/dev to GIGANTYCZNE ZMIANY. Stay tuned..
{kind=link}
No wygląda to zacnie. Z mojego punktu siedzenia Drop Table na replikowanych bazach do giga ficzur.
Na drugim miejscu plasuje się nowy DMF o którym piszesz.
Jedyny problem jaki ogólnie ma MS ze swoim silnikiem bazodanowym od wielu lat, to fakt że nadal nie są w stanie odebrać istniejących klientów Oracle
No to fakt, nie ta liga. Były czasy kiedy MS robił różne testy wydajnościowe i stawał na uszach żeby udowodnić kilka kluczowych argumentów za przejściem. Ale mimo wszystko dalej silnik nie ma takiej skalowalności jak O. Niemniej jednak wszystko robią żeby trochę to zmienić (przepisywanie sqlos od 2014+). Jakoś w najbliższym czasie będę chciał opisać tutaj ciekawy ficzer: https://technet.microsoft.com/en-us/library/ms345392(v=sql.105).aspx