
Z dokumentacji projektu SQLSharp( http://www.sqlsharp.com/download/SQLsharp_Manual.pdf )
| Welcome to SQL# (SQLsharp). SQL# is a small .Net / CLR library (Assembly to be specific) that resides in a SQL Server 2005(or newer) database and provides a suite of User-Defined Functions,StoredProcedures, User-Defined Aggregates, and User-Defined Types. This set of toolsis designed to make thelives of countless SQL Server professionals easier by providing the broad range of commands available inmost other languages outside of SQL (we will not speak of JCL or IBM’s horrendous Net.Data). The User-Defined Functions and Stored Procedures are all prefixed with a „library” name much like you would find inC#, Java / J#, C++, VB.Net, etc. |
O możliwościach CLR zapewne niektórzy już słyszeli. Istnieje metoda na bezpośrednie importowanie specjalnie przygotowanych bibliotek napisanych w C#. Dzięki temu da się rozszerzyć możliwości SQL Server o wiele niespotykanych dotąd funkcjonalności.
Można zatem spodziewać się wielu gotowych narzędzi napisanych w C#, skompilowanych pod CLR i dostępnych w internecie. Taką biblioteką jest projekt SQL# (czyt. SQL Szarp 😉 Oferuje ona prawie 270 320 różnych funkcji. Niektóre z nich mogą okazać się wyjątkowo pomocne.
Niestety, jak mawia popularne powiedzenie „With great power comes great responsibility”. Używanie bibliotek może mocno obciążyc zasoby serwera, dlatego korzystanie z nich w warunkach produkcyjnych w niektórych przypadkach może okazać się katastrofalne. Ale nie zapominajmy o własnych maszynach i instancjach SQL Express, na których swobodnie możemy korzystac z CLR! Pełna lista możliwości w dokumentacji i na stronie: http://www.sqlsharp.com/features/. Częśc rozszerzona jest płatna, ale większość fajnych rzeczy dostępna jest dla każdego 🙂
Projekt pobieramy i instalujemy z jednego pliku SQL. To wyjątkowo wygodne rozwiązanie. Wystarczy uruchomić kod sql (trzeba jedynie skonfigurowac zdefiniowane w nim parametry) i wszystkie assembly trafią do bazy. Instalacja trwa zatem najwyżej minutę.
Przykład:
1. Zobaczmy jak zadziała funkcja SPLIT, czyli rozdzielenie napisu względem konkretnego znaku i zaprezentowanie wyniku w postaci osobnych wierszy:
select * from SQL#.String_Split(
'asdasd,234234,xcvxcv,55,dupa,6767,,op', -- napis do przeszukania
',', -- znak, po ktorym bedziemy rozdzielac
1 -- pokaz nawet puste wartosci (alternatywnie 2 usuwa puste stringi
)
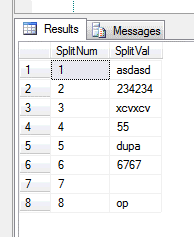
jeśli wiemy, ze napis nie będzie dłuższy niż 8000 znaków (lub 4000 jeśli mamy nchar lub nvarchar) możemy użyć metody SQL#.String_Split4k która powinna być szybsza.
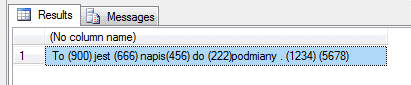
2. Sprawdźmy jak zadziała wyszukiwanie przy pomocy wyrażeń regularnych (Regex) i automatycznej podmianie (RegexReplace)
Spróbujmy podmienić wszystkie wystąpienia ciągu cyfr nimi samymi (znaleziony pattern zwracany jest w zmiennej $0) ale wstawiając przed i po nawiasy ():
select SQL#.RegEx_Replace(
'To 900 jest 666 napis456 do 222podmiany . 1234 5678', -- napis do przeszukania
'([0-9]+)', -- pattern RegEx do wyszukania, uzycie nawiasow spowoduje, ze wynik zostanie przekazany do zmiennej $0
'($0)', -- napis, ktory nalezy wstawic w miejsce znalezionego napisu
-1, -- definiuje ile maksymalnie wystapien moze byc podmienionych, -1 oznacza nieskonczenie wiele :)
1, --starting position czyli od ktorego znaku ma rozpoczac wyszukiwanie i podmiane, uwaga 1 jest poczatkiem napisu, nie 0
NULL --dodatkowe parametry, tutaj niepotrzebne
)
Pomyślnego kombinowania 😉
{kind=link}