Z dokumentacji technet: ( https://technet.microsoft.com/en-us/library/ms190954%28v=sql.105%29.aspx )
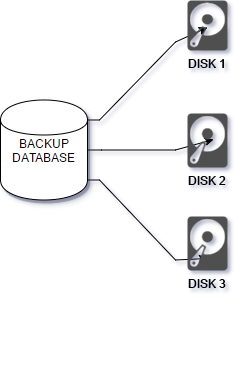
| Using multiple backup devices allows backups to be written to all devices in parallel. Backup device speed is one potential bottleneck in backup throughput. Using multiple devices can increase throughput in proportion to the number of devices used. Similarly, the backup can be restored from multiple devices in parallel. |
W SQL Server możliwe jest zrównoleglenie zapisu backupu aż do 64 plików naraz! Wystarczy, że zdefiniujemy kolejne ścieżki a SQL Server postara się równomiernie rozłożyć na nich pliki. Prócz oczywistych korzyści płynących z oszczędności czasu (zapis do kilku plików w tym samym czasie, ale uwaga – z prędkością najwolniejszego nośnika! ) zyskujemy jeszcze jedną – możemy zaoszczędzić miejsce poprzez rozłożenie plików. Niestety tu jest malutki haczyk 🙂
SQL Server dzieli pliki backupów na takie same wielkości. A więc jeśli backup bazy pierwotnie w jednym pliku zajmuje 100GB zapisując go do dwóch plików każdy będzie miał po 50GB. 100GB na trzy pliki da nam nieco ponad 33GB na kazdy (itd).
Jeśli chcemy wiec zmiescic 100GB backupu na dwóch dyskach, jeden z 30GB wolnego miejsca drugi zas 70GB musimy wykonac podział na tyle plików by każdy z nich był nie większy niż 30GB i każdy zmieścił się na dostępnej przestrzeni (sensownie jest podzielic 100GB/10 plikow każdy po 10GB, trzy pierwsze umieścić na pierwszym dysku, pozostałe zaś na drugim). Oczywiście bez informacji ile zajmuje backup niestety nasze obliczenia nie będą możliwe. Co gorsza backup skompresowany trudniej oszacować. Jest to więc metoda, która w skrajnym przypadku będzie wymagała od nas podejścia prób i błędów ;]
Przykład:
Utworzyłem sztucznie limity pojemności folderów (przy pomocy File Server Resource Manager) i tzw Quoty.

Jak widac są trzy foldery. Jeden który ma 100MB, drugi 200MB a trzeci 300MB. Wgranie do nich plików o większej pojemności zawsze kończy się błędem.
Potrzebuje zatem wykonać backup bazy, której plik może miec maksymalnie 100MB. Mam 8GB bazę, które skompresowany backup waży około 170MB ale do podczas wykonywania potrzebuje okolo 650MB czyli to jest nasz docelowy rozmiar (widać tę wielkość podczas backupu do jednego pliku)
Nie zmieści się w żadnej z dostępnych lokalizacji. Musimy więc go podzielić. Bezpiecznie będzie jeśli pliki będą trochę mniejsze od docelowej wielkości. Dzielimy zatem zatem nasze wymagane 650 przez 90 co daje nam 7,22 a zatem tworzymy 8 plikow backupu.
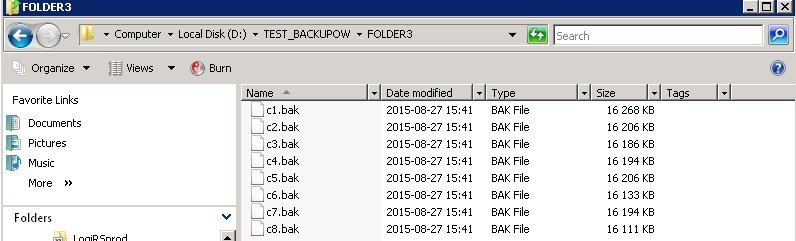
Pierwszy wrzucimy na pierwsza sciezke, dwa kolejne do drugiej a pozostałe do trzeciej. W czasie wykonywania backupu wyglądają one następująco:

Skrypt wykonujący backup:
BACKUP DATABASE [testowa] TO DISK = N'D:\TEST_BACKUPOW\FOLDER1\a1.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER2\b1.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER2\b2.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER3\c1.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER3\c2.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER3\c3.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER3\c4.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER3\c5.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER3\c6.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER3\c7.bak', DISK = N'D:\TEST_BACKUPOW\FOLDER3\c8.bak' WITH NOFORMAT, NOINIT, NAME = N'testowa', SKIP, NOREWIND, NOUNLOAD, STATS = 1 GO
(w management studio, w kreatorze backupu wystarczy w polu DISK podać tyle plików ile nam pasuje)
Po zakończeniu pliki zamiast 47 105 KB mają wielkości mniej więcej koło 16MB (ich zmienny rozmiar wynika z użytej kompresji, gdyby backup nie był kompresowany wszystkie miałyby taki sam rozmiar)
{kind=link}