
Dzisiaj prezentacja prostego sposobu na pozbycie się wszystkich rekordów, które nie są takie same ale niestety mają ten sam klucz.
Do wykonania takiej operacji posłużymy się oczywiście grupowaniem, ale nie tym klasycznym które wszyscy znamy (GROUP BY), a partycjonowaniem danych przy użyciu funkcji okienkowych (PARTITION BY)
Wystarczy ponumerowac rekordy (ROW_NUMBER()) względem zadanej partycji sortując tak by zostały tylko te rekordy, które są dla nas ważne.
Warto również zapamiętac, że tabela użyta w CTE (common table expression, to cos zaczynające się od WITH) może byc przez to CTE modyfikowana! Łącznie z usunięciem 🙂
Do roboty.
Naszym zadaniem jest usunąc wszystkie NAJSTARSZE duplikaty klucza (pole Nazwa) zostawiając jedynie najświeższy rekord (decyduje o tym pole DataDodania)
Tworzymy tabelkę i dodajemy dane.
SET NOCOUNT ON
DECLARE @T TABLE
(
Nazwa VARCHAR(30) ,
DataDodania DATETIME
)
INSERT INTO @t
VALUES ( 'MIPA', '2000-01-01' ),
( 'MIPA', '2002-01-01' ),
( 'MIPA', '2004-01-01' ),
( 'MIPA', '2015-01-01' ),
( 'KUPA', '2002-01-01' ),
( 'KUPA', '2007-01-01' ),
( 'TOMI', '2000-01-01' ),
( 'PIPO', '2010-01-01' ),
( 'PIPO', '2039-01-01' )
SELECT *
FROM @t

Zaczynamy numerować wiersze. Zobaczcie jak wygląda numerowanie z użyciem partycji i sortowaniem malejącym:
WITH CTE
AS ( SELECT NumerWiersza = ROW_NUMBER() OVER ( PARTITION BY Nazwa ORDER BY DataDodania DESC ) ,
*
FROM @t
)
SELECT *
FROM cte

SQL ponumerował nam każdy wiersz nadając jedynkę każdej partycji (grupie wierszy po kolumnie Nazwa). Pozostałe rekordy będą oczywiście numerowane 1+n aż do wystąpienia nowej wartości partycjonowanej.
Dlatego możemy wykonać na powyższym CTE operację usunięcia rekordów, których NumerWiersza będzie większy od jedynki!
WITH CTE
AS ( SELECT NumerWiersza = ROW_NUMBER() OVER ( PARTITION BY NAzwa ORDER BY DataDodania DESC ) ,
*
FROM @t
)
DELETE FROM cte
WHERE NumerWiersza > 1
SELECT *
FROM @t
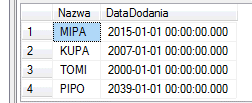
Voilà!
Cały skrypt poniżej:
SET NOCOUNT ON
DECLARE @T TABLE
(
Nazwa VARCHAR(30) ,
DataDodania DATETIME
)
INSERT INTO @t
VALUES ( 'MIPA', '2000-01-01' ),
( 'MIPA', '2002-01-01' ),
( 'MIPA', '2004-01-01' ),
( 'MIPA', '2015-01-01' ),
( 'KUPA', '2002-01-01' ),
( 'KUPA', '2007-01-01' ),
( 'TOMI', '2000-01-01' ),
( 'PIPO', '2010-01-01' ),
( 'PIPO', '2039-01-01' )
SELECT *
FROM @t;
WITH CTE
AS ( SELECT NumerWiersza = ROW_NUMBER() OVER ( PARTITION BY NAzwa ORDER BY DataDodania DESC ) ,
*
FROM @t
)
SELECT *
FROM cte;
WITH CTE
AS ( SELECT NumerWiersza = ROW_NUMBER() OVER ( PARTITION BY NAzwa ORDER BY DataDodania DESC ) ,
*
FROM @t
)
DELETE FROM cte
WHERE NumerWiersza > 1
SELECT *
FROM @t
{kind=link}