
Z dokumentacji technet:
https://msdn.microsoft.com/en-us/library/ms175158%28v=sql.105%29.aspx
| Snapshots can be used for reporting purposes. Also, in the event of a user error on a source database, you can revert the source database to the state it was in when the snapshot was created. Data loss is confined to updates to the database since the snapshot’s creation. |
Możliwe, że niektórzy z Was znają mechanizm „snapshotowania” danych ogólnie przyjęty w technologiach infromatycznych.
Istnieje on w VMware, VirtualBox, HyperV, na kontrolerach macierzy, czy nawet w każdym systemie Windows (rozpoczynając od XP) pod postacią VSS (Volume Shadow [copy] Service) i mechanizmu Copy-on-Write czy nawet na Linuxie, który ma to od 1998r w LVM 🙂
Na czym to polega?
Wystarczy sobie wyobrazić dysk komputera i strony danych jako strony z pewnej książki.
Jeśli chcielibyśmy zmienić kilka zdań na takiej stronie moglibyśmy wyrwać całą kartkę, odłożyć gdzieś na półkę a w jej miejsce wstawić przepisaną na nowo.
Oczywiście z poprawioną treścią, dodając gdzieś pod spodem informację zapisaną ołówkiem:
„to co było tutaj wcześniej znajdziemy w pierwszej przegrodzie po lewej stronie na górnej półce naszej biblioteczki :D”
W ten sposób, jeśli chcielibyśmy odczytać naszą książkę w całości, ale sprzed zmian – wystarczyłoby ją wziąć do ręki i przy okazji zabrać z półki naszą wyrwaną stronę. Tam gdzie dojdziemy do zmienionej strony sugerujemy się adnotacją dopisaną wcześniej.
Taka analogia bardzo dobrze oddaje to, co faktycznie ma miejsce w tego typu mechanizmach i podobnie jak w ww. produktach jest ona także dostępna w SQL Server (od SQL Server 2005 do 2016 niestety tylko w wersjach Enterprise i Developer, od 2016 R2 dostępna również w Standard)
Ja stosuję ją od dawna, jest niesłychanie pomocna szczególnie tam, gdzie częste czynności deweloperskie na sporych bazach mogą doprowadzić do dużego kuku a stosowanie backupów w celu przywrócenia stanu poprzedniego jest wysoce wku…rzające.
Podsumowując
– Tworząc snapshot bazy danych można go później wykorzystać do przywrócenia stanu bazy sprzed zmian, które po nim wystąpiły na zasadzie podobnej do odtworzenia backupu
– Przy tym nie trzeba martwić się o dodatkowe miejsce i czas jak w przypadku backupu. Snapshot waży tyle ile ważyły zmienione strony a czas jego robienia rozkłada się na każdą operację, która modyfikuje dane w oryginalnej bazie.
– z powyższego wynika zatem, że
- Snapshot to nic innego jak migawka danych na moment jego zrobienia
- Dostęp do niej jest tylko read-only
- Uprawnienia do jej odczytu są TAKIE SAME JAK UPRAWNIENIA DO BAZY, Z KTÓREJ POCHODZI SNAPSHOT. Innymi słowy nie można ich później zmienić na snapshocie. (co ma sens jak się pomyśli o tym dłużej)
- Spowalnia to wydajność wykonywania zmian na oryginalnej bazie (każda operacja zapisu generuje co najmniej jedną operację odczytu starej strony i zapisu jej gdzieś na boku zanim wstawiona zostanie jej nowa wersja). Sorry, coś za coś 😉
Przykład
Mamy bazę AdventureWorks2012. Szczegóły na mojej maszynie:
sp_helpdb 'AdventureWorks2012′

Jak widzicie baza ta ma dwa pliki. Jeden plik danych MDF i jeden LOG.
Snapshoty nie opierają się na pliku logu transakcyjnego, toteż należy pamiętać, że jeśli trwa jakaś transakcja to wykonane w niej dotąd zmiany zostaną cofnięte w snapshocie.
Tworząc snapshot mamy obowiązek stworzyć nowe pliki odpowiadające każdemu MDF i NDF.
Czyli w naszym przypadku będzie to odpowiednik logicznej nazwy pliku AdventureWorks2012_Data.mdf o nazwie AdventureWorks2012_Data (plik o id 1 na powyższym obrazku)
Tworzymy snapshot
Polecenie tworzące snapshot jest bardzo proste:
CREATE DATABASE AdventureWorks2012_SNAPSHOT ON ( NAME = AdventureWorks2012_Data, /*nazwa logiczna pliku danych czyli tego z C:\SQL\SQL_DATA\AdventureWorks2012_Data.mdf */ FILENAME = 'C:\SQL\SNPASHOT\AdventureWorks2012_SNAPSHOT.ss' /*nazwa pliku snapshotu, który SQL sam stworzy i to właśnie w nim będzie odkładał wszystkie strony danych sprzed zmian */ ) AS SNAPSHOT OF AdventureWorks2012; /*nazwa bazy, z której tworzymy snapshot*/ GO
W czasie mniejszym niż jedna sekunda powyższe zapytanie kończy się poprawnie a na dysku powstaje nowy plik AdventureWorks2012_SNAPSHOT.ss
UWAGA: Windows będzie pokazywał wielkość pliku taką samą jak oryginalny plik MDF. Nie dajcie się oszukać. Zobaczcie jaki jest size on disk!!
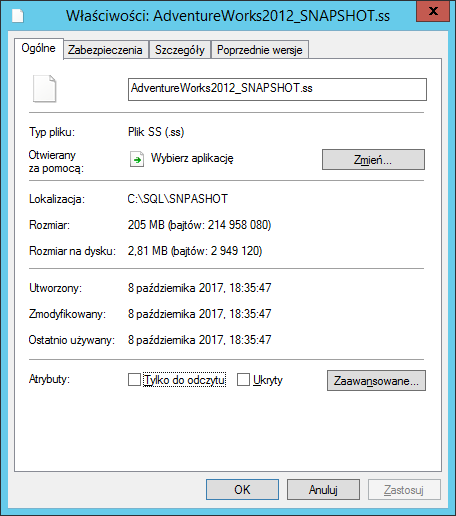
Gdzie w takim razie szukac snapshota w Management Studio?
Wystarczy rozwinąć gałąź „Database Snapshots”:
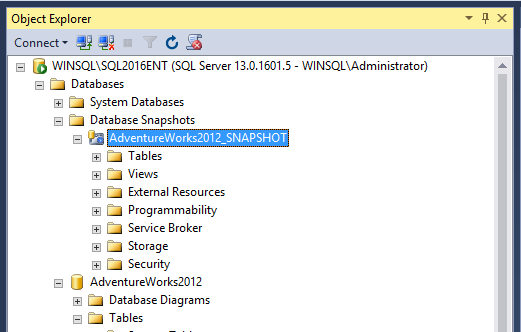
Jak widać struktura katalogów jest praktycznie taka sama jak dla zwykłej bazy. Wszystkie obiekty dostępne są w trybie do odczytu.
No dobrze.
Pora na zmiany w bazie.
Usuwamy przykładową tabelę z bazy:
DROP TABLE AdventureWorks2012.[Sales].[SalesOrderDetail]
Nie mamy już możliwości dostania się do niej z bazy AdventureWorks2012
SELECT * FROM AdventureWorks2012.[Sales].[SalesOrderDetail]

Czy zatem można to zrobic na napshocie? Można!
SELECT * FROM AdventureWorks2012_SNAPSHOT.[Sales].[SalesOrderDetail]

Po tych operacjach snapshot waży dokładnie tyle samo ile ważył podczas stworzenia. Widać przy okazji, że drop table to polecenie, która zmienia tylko metadane. Dopiero nowe dane (innej tabeli lub jakiejś nowo utworzonej) nadpiszą fizycznie to miejsce, w którym siedziała tabela SalesOrderDetail.
Przywracamy bazę ze snapshotu
Jak zatem przywrócić bazę do stanu snapshota? W normalnej sytuacji trzeba byłoby przywrócić backup (jeśli jakiś w ogóle był..)
My jednak mamy snapshota a cała operacja będzie nas kosztowała jedynie napisanie polecenia i kilkanaście milisekund:
USE master GO RESTORE DATABASE AdventureWorks2012 FROM database_snapshot = 'AdventureWorks2012_SNAPSHOT'; GO
ZOBACZ TEŻ:
CREATE DATABASE AS SNAPSHOT – Generowanie prostego skryptu tworzącego snapshot bieżącej bazy
{kind=link}