
This article is obsolete. A lot has changed since 2018, both the documentation and ADF contain a lot of key information, so I recommend that you refer to the official sources like “Delta copy”, or “ADF templates” link: https://docs.microsoft.com/en-us/azure/data-factory/solution-template-delta-copy-with-control-table
This post explains things that are difficult to find even in English. That’s why I will break my rule and will not write it in my native language! Po wersję polską zapraszam do google translate :>
Table of Contents
Introduction
Loading data using Azure Data Factory v2 is really simple. Just drop Copy activity to your pipeline, choose a source and sink table, configure some properties and that’s it – done with just a few clicks!
But what if you have dozens or hundreds of tables to copy? Are you gonna do it for every object?
Fortunately, you do not have to do this! All you need is dynamic parameters and a few simple tricks 🙂
Also, this will give you the option of creating incremental feeds, so that – at next run – it will transfer only newly added data.
Mappings
Before we start diving into details, let’s demystify some basic ADFv2 mapping principles.
- Copy activity doesn’t need to have defined column mappings at all,
- it can dynamically map them using its own mechanism which retrieves source and destination (sink) metadata,
- if you use polybase, it will do it using column order (1st column from source to 1st column at destination etc.),
- if you do not use polybase, it will map them using their names but watch out – it’s case sensitive matching!
- So all you have to do is to just keep the same structure and data types on the destination tables (sink), as they are in a source database.
Bear in mind, that if your columns are different between source and destination, you will have to provide custom mappings. This tutorial doesn’t show how to do it, but it is possible to pass them using “Get metadata” activity to retrieve column specification from the source, then you have to parse it and pass as JSON structure into the mapping dynamic input. you can read about mappings in official documentation: https://docs.microsoft.com/en-us/azure/data-factory/copy-activity-schema-and-type-mapping
String interpolation – the key to success
My entire solution is based on one cool feature, that is called string interpolation. It is a part of built-in expression engine, that simply allows you to just inject any value from JSON object or an expression directly into string input, without any concatenate functions or operators. It’s fast and easy. Just wrap your expression between @{ ... } . It will always return it as a string.
Below is a screen from official documentation, that clarifies how this feature works:

Read more about JSON expressions at https://docs.microsoft.com/en-us/azure/data-factory/control-flow-expression-language-functions#expressions
So what we are going to do? :>
Good question 😉
In my example, I will show you how to transfer data incrementally from Oracle and PostgreSQL tables into Azure SQL Database.
All of this using configuration stored in a table, which in short, keeps information about Copy activity settings needed to achieve our goal 🙂
Adding new definitions into config will also automatically enable transfer for them, without any need to modify Azure Data Factory pipelines.
So you can transfer as many tables as you want, in one pipeline, at once. Triggering with one click 🙂
Every process needs diagram :>
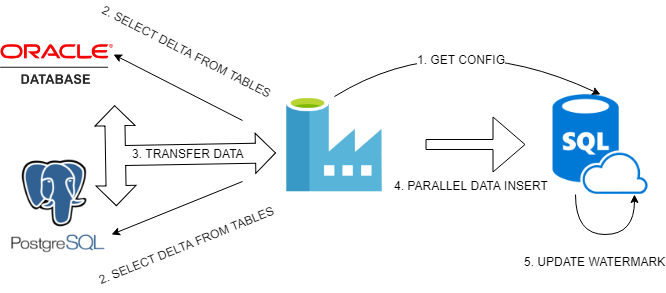
Basically, we will do:
- Get configuration from our config table inside Azure SQL Database using Lookup activity, then pass it to Filter activity to split configs for Oracle and PostgreSQL.
- In Foreach activity created for every type of database, we will create simple logic that retrieves maximum update date from every table.
- Then we will prepare dynamically expressions for SOURCE and SINK properties in Copy activity. MAX UPDATEDATE, retrieved above, and previous WATERMARK DATE, retrieved from config, will set our boundaries in WHERE clause. Every detail like table name or table columns we will pass as a query using string interpolation, directly from JSON expression. Sink destination will be also parametrized.
- Now Azure Data Factory can execute queries evaluated dynamically from JSON expressions, it will run them in parallel just to speed up data transfer.
- Every successfully transferred portion of incremental data for a given table has to be marked as done. We can do this saving MAX UPDATEDATE in configuration, so that next incremental load will know what to take and what to skip. We will use here: Stored procedure activity.
About sources
I will use PostgreSQL 10 and Oracle 11 XE installed on my Ubuntu 18.04 inside VirtualBox machine.
In Oracle, tables and data were generated from EXMP/DEPT samples delivered with XE version.
In PostgreSQL – from dvd rental sample database: http://www.postgresqltutorial.com/postgresql-sample-database/
I simply chose three largest tables from each database. You can find them in a configuration shown below this section.
Every database is accessible from my Self-hosted Integration Runtime. I will show an example how to add the server to Linked Services, but skip configuring Integration Runtime. You can read about creating self-hosted IR here: https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime.
About configuration
In my Azure SQL Database I have created a simple configuration table:

Id is just an identity value, SRC_name is a type of source server (ORA or PG).
SRC and DST tab columns maps source and destination objects. Cols defines selected columns, Watermark Column and Value stores incremental metadata.
And finally Enabled just enables particular configuration (table data import).
This is how it looks with initial configuration:

Create script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [load].[cfg]( [id] [SMALLINT] IDENTITY(1,1) NOT NULL, [SRC_name] [NVARCHAR](128) NOT NULL, [SRC_tab] [NVARCHAR](128) NOT NULL, [DST_tab] [NVARCHAR](128) NOT NULL, [Cols] [NVARCHAR](MAX) NOT NULL, [WatermarkColumn] [NVARCHAR](128) NOT NULL, [WatermarkValue] [DATETIME] NOT NULL, [Enabled] [BIT] NOT NULL, CONSTRAINT [PK_load] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO ALTER TABLE [load].[cfg] ADD CONSTRAINT [DF__cfg__WatermarkVa__4F7CD00D] DEFAULT ('1900-01-01') FOR [WatermarkValue] GO |
EDIT 19.10.2018
Microsoft announced, that now you can parametrize also linked connections!
Let’s get started (finally :P)
Preparations!
Go to your Azure Data Factory portal @ https://adf.azure.com/
Select Author button with pencil icon:

Creating server connections (Linked Services)
We can’t do anything without defining Linked Services, which are just connections to your servers (on-prem and cloud).
- Go to
 and click
and click 
- Find your database type, select and click

- Give all needed data, like server ip/host, port, SID (Oracle need this), login and password.
- You can
 if everything is ok. Click Finish to save your connection definition.
if everything is ok. Click Finish to save your connection definition.
I have created three connections. Here are their names and server types:

Creating datasets
Creating linked services is just telling ADF what are connection settings (like connection strings).
Datasets, on the other hand, points directly to database objects.
BUT they can be parametrized, so you can just create ONE dataset and use it passing different parameters to get data from multiple tables within same source database 🙂
Source datasets
Source datasets don’t need any parameters. We will later use built-in query parametrization to pass object names.
- Go to
 and click + and choose
and click + and choose 
- Choose your datataset type, for example

- Rename it just as you like. We will use name: “ORA”
- Set proper Linked service option, just like this for oracle database:

- And that’s it! No need to set anything else. Just repeat these steps for every source database, that you have.
In my example, I’ve created two source datasets, ORA and PG

As you can see, we need to create also the third dataset. It will work as a source too, BUT also as a parametrizable sink (destination). So creating it is little different than others.
Sink dataset
Sinking data needs one more extra parameter, which will store destination table name.
- Create dataset just like in the previous example, choose your destination type. In my case, it will be Azure SQL Database.
- Go to
 , declare one String parameter called “TableName”. Set the value to anything you like. It’s just dummy value, ADF just doesn’t like empty parameters, so we have to set a default value.
, declare one String parameter called “TableName”. Set the value to anything you like. It’s just dummy value, ADF just doesn’t like empty parameters, so we have to set a default value. - Now, go to
 , set Table as dynamic content. This will be tricky :). Just click “Select…”, don’t choose any value, just click somewhere in empty space. The magic option “Add dynamic content” now appears! You have to click it or hit alt+p.
, set Table as dynamic content. This will be tricky :). Just click “Select…”, don’t choose any value, just click somewhere in empty space. The magic option “Add dynamic content” now appears! You have to click it or hit alt+p. 
- “Add Dynamic Content” windows is now visible. Type: “@dataset().TableName” or just click “TableName” in “Parameters” section below “Functions”.
- The table name is now parameterized. And looks like this:


Parametrizable PIPELINE with dynamic data loading.
Ok, our connections are defined. Now it’s time to copy data :>
Creating pipeline
- Go to you ADF and click PLUS symbol near search box on the left and choose “Pipeline“:
- Reanme it. I will use “LOAD DELTA“.
- Go to Parameters, create new String parameter called ConfigTable. Set value to our configuration table name: load.cfg . This will simply parametrize you configuration source. So that in the future it would be possible to load a completely different set of sources by changing only one parameter :>
- In case you missed it, SAVE your work by clicking “Save All” if you’re using GIT or “Publish All” if not ;]

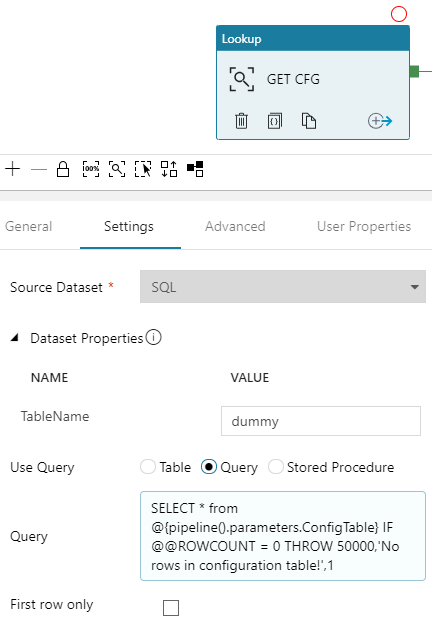
Creating Lookup – GET CFG
First, we have to get configuration. We will use Lookup activity to retrieve it from the database.
-
- Drag and drop
 into your pipline
into your pipline - Rename it. This is important, we will use this name later in our solution. I will use value “GET CFG“.
- In “Settings” choose

- Now, don’t bother TableName set to dummy :> Just in “Use Query” set to “Query“, click “Add dynamic content” and type:
12SELECT * from @{pipeline().parameters.ConfigTable}IF @@ROWCOUNT = 0 THROW 50000,'No rows in configuration table!',1 - Unmark “First row only“, we need all rows, not just first. All should look like this:
- Drag and drop
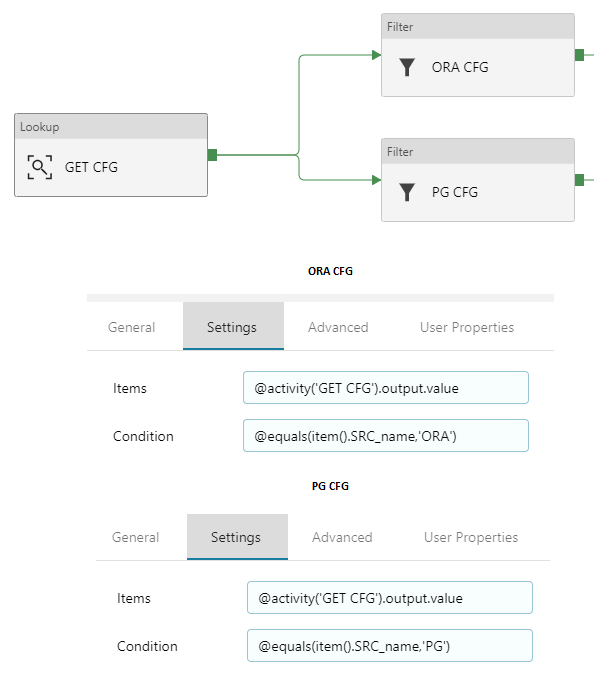
Creating Filters – ORA CFG & PG CFG
Now we have to split configs for oracle and PostgreSQL. We will use Filter activity on rows retrieved in “GET CFG” lookup.
- Drag and drop
 twice.
twice. - Rename the first block to “ORA CFG“, second to “PG CFG“.
- Now go to “ORA CFG“, then “Settings“.
- In Items, click Add dynamic content and type: @activity('GET CFG').output.value . As you probably guess, this will point directly to GET CFG output rows 🙂
- In Condition, click Add dynamic content and type: @equals(item().SRC_name,'ORA') . We have to match rows for oracle settings. So we know, that there is a column in config table called “SRC_name“. We can use it to filter out all rows, except that with value ‘ORA’ 🙂 .
- Do the same with lookup activity “PG CFG“. Of course, change the value for a condition.
It should look like this:
Creating ForEach – FOR EACH ORA & FOR EACH PG
Now it’s time to iterate over each row filtered in separate containers (ORA CFG and PG CFG).
- Drag and drop two
 blocks, rename them as “FOR EACH ORA” and “FOR EACH PG“. Connect each to proper filter acitivity. Just like in this example:
blocks, rename them as “FOR EACH ORA” and “FOR EACH PG“. Connect each to proper filter acitivity. Just like in this example: 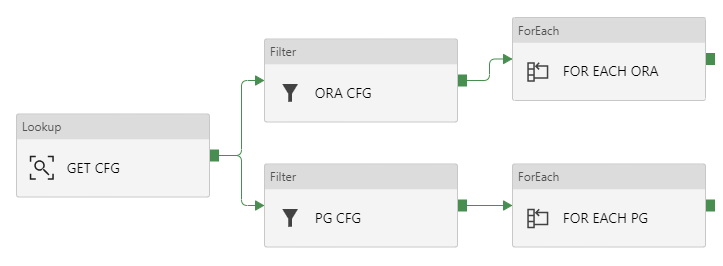
- Click “FOR EACH ORA“, go to “Settings“, in Items clik Add dynamic content and type: @activity('ORA CFG').output.value . We are telling ForEach, that it has to iterate over results returned in “ORA CFG”. They are stored in JSON array.
- Do this also in FOR EACH PG. Type: @activity('PG CFG').output.value
- Now, you can edit Activities and add only “WAIT” activity to debug your pipeline. I will skip this part. Just remember to delete WAIT block at the end of your tests.

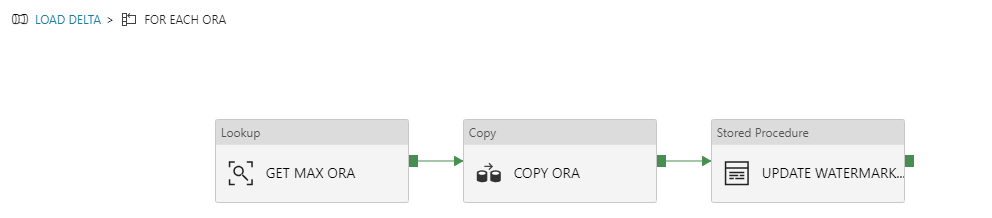
Inside ForEach – GET MAX ORA -> COPY ORA -> UPDATE WATERMARK ORA
Place these blocks into FOR EACH ORA. Justo go there, click “Activities” and then ![]()
And every column in that row, can be reached just by using @item().ColumnName .
Remember, that you can surround every expression in brackets @{ } to use it as a string interpolation. Then you can concatenate it with other strings and expressions just like that: Value of the parameter WatermarkColumn is: @{item().WatermarkColumn}
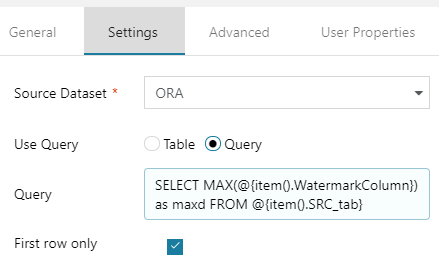
GET MAX ORA
- Go to “GET MAX ORA“, then Settings
- Choose your source dataset “ORA“, Use Query: “Query” and click Add dynamic content
- Type SELECT MAX(@{item().WatermarkColumn}) as maxd FROM @{item().SRC_tab} . This will get a maximum date in your watermark column. We will use it as RIGHT BOUNDRY for delta slice.
- Check if First row only is turned on.
It should look like this:
COPY ORA
Now the most important part :> Copy activity with a lot of parametrized things… So pay attention, it’s not so hard to understand but every detail matters.
Source
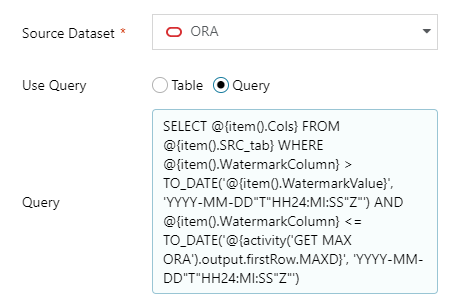
- In source settings, choose Source Dataset to ORA, in Use query select Query.
- Below Query input, click Add dynamic content and paste this:
12345678910SELECT@{item().Cols} FROM @{item().SRC_tab}WHERE@{item().WatermarkColumn} >TO_DATE('@{item().WatermarkValue}', 'YYYY-MM-DD"T"HH24:MI:SS"Z"')AND@{item().WatermarkColumn} <=TO_DATE('@{activity('GET MAX ORA').output.firstRow.MAXD}', 'YYYY-MM-DD"T"HH24:MI:SS"Z"')
Now, this needs some explanation 🙂

- ORA CFG output has all columns and their values from our config.
- We will use SRC_tab as table name, Cols as columns for SELECT query, WatermatkColumn as LastChange DateTime column name and WatermarkValue for LEFT BOUNDRY (greater than, >).
- GET MAX ORA output stores date of a last updated row in the source table. So this is why we are using it as a RIGHT BOUNDRY (less than or equal, <=)
- And the tricky thing, ORACLE doesn’t support implicit conversion from the string with ISO 8601 date. So we need to extract it properly with TO_DATE function.
So the source is a query from ORA dataset:
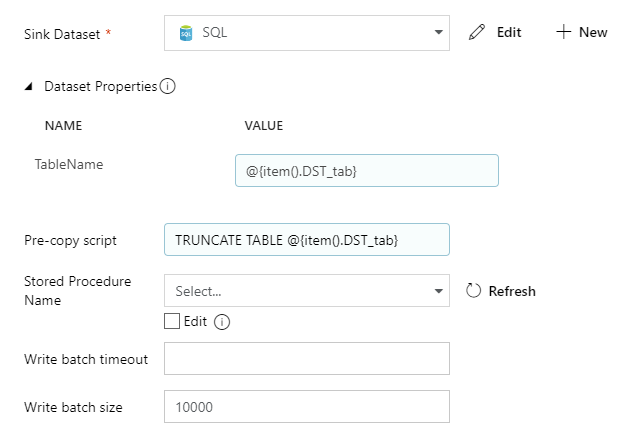
Sink
Sink is our destination. Here we will set parametrized table name and truncate query.
- Select

- Parametrize TableName as dynamic content with value: @{item().DST_tab}
- Also, do the same with Pre-copy script and put there: TRUNCATE TABLE @{item().DST_tab}
It should look like this:
Mappings and Settings
All other things should just be set to defaults. You don’t have to parametrize mappings if you just copy data from and to tables that have the same structure.
Of course, you can dynamically create them if you want, but it is a good practice to transfer data 1:1 – both structure and values from source to staging.
UPDATE WATERMARK ORA
Now we have to confirm, that load has finished and then update previous watermark value with the new one.
We will use a stored procedure. The code is simple:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE PROC [load].[usp_UpdateWatermark] @id SMALLINT, @NewWatermark DATETIME AS SET NOCOUNT ON; UPDATE load.cfg SET WatermarkValue = @NewWatermark WHERE id = @id; GO |
Create it on your Azure SQL database. Then use it in ADF:
- Drop
 into project, connect constraint from COPY ORA into it. Rename as “UPDATE WATERMARK ORA” and view properties.
into project, connect constraint from COPY ORA into it. Rename as “UPDATE WATERMARK ORA” and view properties. - In SQL Account set

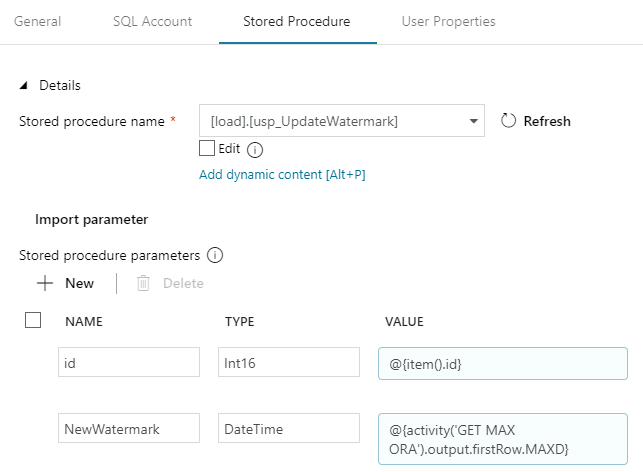
- Now go to “Stored Procedure”, select our procedure name and click “Import parameter”.
- Now w have to pass values for procedure parametrs. And we will also parametrize them. Id should be @{item().id} and NewWatermatk has to be: @{activity('GET MAX ORA').output.firstRow.MAXD} .

And basically, that’s all! This logic should copy rows from all Oracle tables defined in the configuration.
We can now test it. This can be done with “Debug” or just by triggering pipeline run.
If everything is working fine, we can just copy/paste all content from “FOR EACH ORA” into “FOR EACH PG“.
Just remember to properly rename all activities to reflect new source/destination names (PG). Also, all parameters and SELECT queries have to be redefined. Luckily PostgreSQL support ISO dates out of the box.
Source code
Here are all components in JSON. You can use them to copy/paste logic directly inside ADF V2 code editor or save as files in GIT repository.
Below is source code for pipeline only. All other things can be downloaded in zip file in “Download all” at the bottom of this article.
Pipeline
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 |
{ "name": "LOAD DELTA", "properties": { "activities": [ { "name": "GET CFG", "type": "Lookup", "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false }, "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": { "value": "SELECT * from @{pipeline().parameters.ConfigTable}\nIF @@ROWCOUNT = 0 THROW 50000,'ojej...',1", "type": "Expression" } }, "dataset": { "referenceName": "SQL", "type": "DatasetReference", "parameters": { "TableName": "dummy" } }, "firstRowOnly": false } }, { "name": "FOR EACH ORA", "type": "ForEach", "dependsOn": [ { "activity": "ORA CFG", "dependencyConditions": [ "Succeeded" ] } ], "typeProperties": { "items": { "value": "@activity('ORA CFG').output.value", "type": "Expression" }, "isSequential": false, "activities": [ { "name": "COPY ORA", "type": "Copy", "dependsOn": [ { "activity": "GET MAX ORA", "dependencyConditions": [ "Succeeded" ] } ], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false }, "userProperties": [ { "name": "Destination", "value": "@{item().DST_tab}" } ], "typeProperties": { "source": { "type": "OracleSource", "oracleReaderQuery": { "value": "SELECT \n @{item().Cols} FROM @{item().SRC_tab} \n\nWHERE \n\n@{item().WatermarkColumn} > \nTO_DATE('@{item().WatermarkValue}', 'YYYY-MM-DD\"T\"HH24:MI:SS\"Z\"')\nAND\n@{item().WatermarkColumn} <=\nTO_DATE('@{activity('GET MAX ORA').output.firstRow.MAXD}', 'YYYY-MM-DD\"T\"HH24:MI:SS\"Z\"')", "type": "Expression" } }, "sink": { "type": "SqlSink", "writeBatchSize": 10000, "preCopyScript": { "value": "TRUNCATE TABLE @{item().DST_tab}", "type": "Expression" } }, "enableStaging": false, "cloudDataMovementUnits": 0 }, "inputs": [ { "referenceName": "ORA", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SQL", "type": "DatasetReference", "parameters": { "TableName": { "value": "@{item().DST_tab}", "type": "Expression" } } } ] }, { "name": "GET MAX ORA", "type": "Lookup", "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false }, "typeProperties": { "source": { "type": "OracleSource", "oracleReaderQuery": { "value": "SELECT MAX(@{item().WatermarkColumn}) as maxd FROM @{item().SRC_tab} ", "type": "Expression" } }, "dataset": { "referenceName": "ORA", "type": "DatasetReference" } } }, { "name": "UPDATE WATERMARK ORA", "type": "SqlServerStoredProcedure", "dependsOn": [ { "activity": "COPY ORA", "dependencyConditions": [ "Succeeded" ] } ], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false }, "typeProperties": { "storedProcedureName": "[load].[usp_UpdateWatermark]", "storedProcedureParameters": { "id": { "value": { "value": "@{item().id}", "type": "Expression" }, "type": "Int16" }, "NewWatermark": { "value": { "value": "@{activity('GET MAX ORA').output.firstRow.MAXD}", "type": "Expression" }, "type": "DateTime" } } }, "linkedServiceName": { "referenceName": "AzureSQL", "type": "LinkedServiceReference" } } ] } }, { "name": "ORA CFG", "type": "Filter", "dependsOn": [ { "activity": "GET CFG", "dependencyConditions": [ "Succeeded" ] } ], "typeProperties": { "items": { "value": "@activity('GET CFG').output.value", "type": "Expression" }, "condition": { "value": "@equals(item().SRC_name,'ORA')", "type": "Expression" } } }, { "name": "PG CFG", "type": "Filter", "dependsOn": [ { "activity": "GET CFG", "dependencyConditions": [ "Succeeded" ] } ], "typeProperties": { "items": { "value": "@activity('GET CFG').output.value", "type": "Expression" }, "condition": { "value": "@equals(item().SRC_name,'PG')", "type": "Expression" } } }, { "name": "FOR EACH PG", "type": "ForEach", "dependsOn": [ { "activity": "PG CFG", "dependencyConditions": [ "Succeeded" ] } ], "typeProperties": { "items": { "value": "@activity('PG CFG').output.value", "type": "Expression" }, "isSequential": false, "activities": [ { "name": "Copy PG", "type": "Copy", "dependsOn": [ { "activity": "GET MAX PG", "dependencyConditions": [ "Succeeded" ] } ], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false }, "userProperties": [ { "name": "Destination", "value": "@{item().DST_tab}" } ], "typeProperties": { "source": { "type": "RelationalSource", "query": { "value": "SELECT @{item().Cols} FROM @{item().SRC_tab} \n\nWHERE \n\n@{item().WatermarkColumn} > \n'@{item().WatermarkValue}'\nAND\n@{item().WatermarkColumn} <=\n'@{activity('GET MAX PG').output.firstRow.MAXD}'", "type": "Expression" } }, "sink": { "type": "SqlSink", "writeBatchSize": 10000, "preCopyScript": { "value": "TRUNCATE TABLE @{item().DST_tab}", "type": "Expression" } }, "enableStaging": false, "cloudDataMovementUnits": 0 }, "inputs": [ { "referenceName": "PG", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SQL", "type": "DatasetReference", "parameters": { "TableName": { "value": "@{item().DST_tab}", "type": "Expression" } } } ] }, { "name": "GET MAX PG", "type": "Lookup", "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false }, "typeProperties": { "source": { "type": "RelationalSource", "query": { "value": "SELECT MAX(@{item().WatermarkColumn}) as maxd FROM @{item().SRC_tab} ", "type": "Expression" } }, "dataset": { "referenceName": "PG", "type": "DatasetReference" } } }, { "name": "UPDATE WATERMARK PG", "type": "SqlServerStoredProcedure", "dependsOn": [ { "activity": "Copy PG", "dependencyConditions": [ "Succeeded" ] } ], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false }, "typeProperties": { "storedProcedureName": "[load].[usp_UpdateWatermark]", "storedProcedureParameters": { "id": { "value": { "value": "@{item().id}", "type": "Expression" }, "type": "Int16" }, "NewWatermark": { "value": { "value": "@{activity('GET MAX PG').output.firstRow.MAXD}", "type": "Expression" }, "type": "DateTime" } } }, "linkedServiceName": { "referenceName": "AzureSQL", "type": "LinkedServiceReference" } } ] } } ], "parameters": { "ConfigTable": { "type": "String", "defaultValue": "load.cfg" } } } } |
Download all
{kind=link}
Michal,
QQ, Does the table has to pre exists on target database? I still get TABLE IS REQUIRED FOR COPY ACTIVITY. I cannot bypass that ERROR
Here is the sink activity updated .
“sink”: {
“type”: “SqlDWSink”,
“allowPolyBase”: false,
“writeBatchSize”: 10000,
“preCopyScript”: {
“value”: “TRUNCATE TABLE @{item().DST_tab}”,
“type”: “Expression”
},
“tableOption”: {
“value”: “@{item().DST_tab}”,
“type”: “Expression”
},
“disableMetricsCollection”: false
},
“enableStaging”: false
},
“inputs”: [
{
“referenceName”: “ONPREM”,
“type”: “DatasetReference”
}
],
“outputs”: [
{
“referenceName”: “AzureSqlDW”,
“type”: “DatasetReference”,
“parameters”: {
“TableName”: {
“value”: “@{item().DST_tab}”,
“type”: “Expression”
}
Oh, you mean you don’t have this table on your sink side?
So that is! YES, having tables is obligatory. There is no code which creates them on the fly.
ok. so if I create the tables on the sink side, then I should be able to bypass that error.
I created the target table. However, I got the same error message when debugging it. TABLE IS REQUIRED FOR COPY ACTIVITY.
hmm, that’s odd. I just sent you an e-mail. Maybe we should continue there to just give me more infos (screens, etc)
Hi Michael, I’m also getting the same error “TABLE IS REQUIRED FOR COPY ACTIVITY.”
Did you manage to sort this for Daniel? is so, can you share the solution?
Much appreciated
Hi Omar.
The problem was (probably) with a value given in table name, that was not declared as expression (but just a regular value, check “Add dynamic content”). Also, some connectors (like Azure Data Warehouse) are expecting schema name and table name in a separate fields. Passing it only in the first can bring unexpected errors like “TABLE IS REQUIRED FOR COPY ACTIVITY.” or “Please select a table for your dataset”. So you need to support two parameters for the sink, schema and table name.
Hope that will help you.
Michal
I am trying to copy from service now to on premises SQL and keeping getting error inner activity failed. I would really appreciate your assistance.
Hi Michal – Thanks for the wonderful post.
How could I join the Lookup output with Metadata output before passing to foreach.
I would like to process the files from Gen2 to SQL Database based on modified time.
1) I am using the lookup to get the destination table name and source directory name
2) I am using the meta data to get the file name from the passed source directory based of modified time.
I require to combine step 1 and 2 information to pass foreach to process the list of files added to a source directory to the destination SQL table.
Thanks
Hi Michał,
How can i load data incrementally, if i do not have water mark column at source?
Thanks
Venkat
Well, it depends. Is there any other column that indicates update/insert date? If not, then it all depends on yours database system, if it has any kind of mechanism that can handle changes in history like change data capture in sql server. If there is nothing, then you can still use triggers to mark update date, perhaps in a different table storing there only key and watermark date. But triggers are the last resort, as they can bring a lot of transactional and performens issues in many scenarios.
Hi Michal,
Thanks for you comment, please assume that you are not allowed(schema changes) to do anything at source, you have only read permissions. Please suggest an approach.
Thanks
Venkat
Well, this is of course the worst scenario. Even if your key is an incremental number/lexicographically ordered string, you can not detect update/delete changes to your data.
In such situations I saw several possible ways of detecting changes by making a mechanism to calculate differences based upon some algorithm.
For example, if it is sql server, you can use two functions (not only one, since it will generate collisions to often) checksum and checksum_bin over all columns, then compare the calculated values with previously generated ones. You need, of course, to store them first somewhere, the primary key and checksum numbers. This mechanism is not ideal, a pair of checksums can generate exactly the same numbers even if some of the columns were changed. That is unfortunate, but rare (anyway I was able to generate such case once in my life)
You can use better hash function, like hashbytes but you need to cast every value to a string, and it is really slow… Like 20 times slower than checksum. And the delete and insert makr just using traditiinal full join with null and not null detection.
It always depends on the size of the data. Sometimes it is better to just do the full and by this time, process the change of adding additional watermark columns, even if it will take months…
Very Impressive Azure Tutorial. The content seems to be pretty exhaustive and excellent and will definitely help in learning Azure Tutorial.I’m also a learner taken up Azure Training and I think your content has cleared some concepts of mine
Thanks a lot! 🙂
Very very useful article to understand & Implement. I have a request though it may not be related to ADFV2. Many of my source tables in My SQL Server do not have any timestamp columns; So in that case what could be the option to identify the delta? The SQL DB i am using is the secondary replica of an Always On availability group where i am not able to enable CDC. Any thoughts or ideas you could share will be very helpful,
Thanks again
Sree
Hi Sree.
Well, this question was raised a few comments above by Venkat.
You do not have a lot of options here if you have only the secondary replica and can’t make any changes to the primary.
Again, I designed once a mechanism that was using two functions: CHECKSUM and BINARY_CHECKSUM, use them both over all columns to identify changes (comparing those two numbers against last check for particular primary key).
But unfortunately, two or three times in the history of that system (few years), there were “collisions”. And by the “collision” I mean two or more columns were updated on a row and even if they had different values before and after the update, both checksums were exactly the same. Therefore I implemented additional logic, a checker, that once in a week was comparing source and target, column by column, value by value (full join with a lot WHERE clause).
Checksums are good for building hash indexes on the fly, in short period, but for a long time can make issues 😐
I also saw a logic that was using HASHBYTES, but it’s more complex and resource consuming than CHECKSUM. I do not recommend using it AT ALL!
HASHBYTES requires STRING (nvarchar(max)) as an argument. So you need to CAST/CONVERT every value, concatenate it using some separating sign (like dash or comma) and use it to generate the value… Anyway, it’s ugly, slow and not bulletproof…
For instance, if you will use ‘-‘ as a separate string, just imagine two columns and their values:
col1 = ‘val’, col2 = ‘-val’. Concatenated with ‘-‘ gives: ‘val–val’
After the update, set col1 = ‘val-‘, col2 = ‘val’. Concatenated with ‘-‘ gives ‘val–val’
It’s obvious that HASHBYTES will not detect the change here and generated hash will be the same, so the algorithm will not detect any change even if there was an UPDATE statement.
In your case DELTA is not possible. You can use some additional logic to detect the changes, but it requires you to make a full scan of the source and having some issues with 100% detection (only 99,9%)
I suggest to focus on the primary replica and try to enable CDC.
Adding CDC there should make it replicated to the secondary and you can use it there (note that only CDC will work like this, Change tracking will not). Confirmed here: https://dba.stackexchange.com/questions/22614/can-cdc-or-change-tracking-be-against-a-read-only-secondary
Thank you for your suggestion Michał. I will work on the CDC part.. however i am also exploring the option of having one Node (Secondary) on the Azure it self…
(Sorry saw your responses after i posted my query).
Thank you
Sree
Thank you very much for this super simple and elaborate explanation.
I have a question not related to incremental copy but full copy sql to sql.
1. I am planning to use the overwrite methodology of ADF in the destination each time a copy occurs. I want to use a staging table and write a precopyscript that the destination table is only deleted once the ADF copy succeeds. If the copy does not succeed, I create a destination table with the staged table. Any pointers on how to do this better?
2. The key constraints on the source table are not carried over to the destination when a sql copy occurs. Any idea how to carry forward the source key constraints on the destination?
Hi Priyanka,
Regarding the first point, I’m not sure if I get this right. Could you explain it a little bit deeper? :> Just maybe by a simple example, like an algorithm in few steps. So far I’m not sure what is the destination, what is the source and where ADF is used here 🙂
And the second, well.. U need to unfortunately do it the hard way.
If you are not having tables on the destination and you want to create them dynamically with all depended objects, like PK, default constraints, check constraints or foreign key (and watch out with both of them, this requires you to upload the data in specific order to meet enforced logic)
THEN you need to use some external scripts to first, script them out, fetch the content, then recreate them on the destination.
For example using this: https://www.mssqltips.com/sqlservertip/3443/script-all-primary-keys-unique-constraints-and-foreign-keys-in-a-sql-server-database-using-tsql/
It will not be easy, but you can try to implement such procedure to return the text of all objects as CREATE,ALTER statements then apply fetched context as sql on the destination.
Hi Michael,
I am using ADF to copy my csv data file into SQL.
in the Pre-script , I used TRUNCATE TABLE @{item().name} in the sink but when the pipeline runs, I can see duplicate results in SQL, clearly the truncate function is not working as expected.
Also,
the sink dataset has properties: name: tablename, value: @item().name [dynamic content]
and SQL tables are stored in a schema as: [schemaname].[tablename]
HMm, not sure what’s happening. But in my example I use “TRUNCATE TABLE @{item().DST_tab}” not “@item().name”. Are you sure you are using the right destination reference?
Hi Michael
I was so happy to get this amazing post and tried to use it. I have the below error and don’t know the reason. This is happening when I debug the first lookup task. The problem is on source when I use the query
SELECT * from @{pipeline().parameters.ConfigTable}
IF @@ROWCOUNT = 0 THROW 50000,’No rows in configuration table!’,1
Please advise as I am stuck here.
Error message on the
“errorCode”: “2100”,
“message”: “Failure happened on ‘Source’ side. ErrorCode=UserErrorOdbcOperationFailed,’Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ERROR [42000] [Microsoft][ODBC Oracle Wire Protocol driver][Oracle]ORA-00933: SQL command not properly ended,Source=Microsoft.DataTransfer.ClientLibrary.Odbc.OdbcConnector,”Type=System.Data.Odbc.OdbcException,Message=ERROR [42000] [Microsoft][ODBC Oracle Wire Protocol driver][Oracle]ORA-00933: SQL command not properly ended,Source=msora28.dll,'”,
“failureType”: “UserError”,
“target”: “GET CFG”,
“details”: []
Hi Tesfa.
This table lookup query was designed to work with MS SQL Server, not Oracle.
You need to rewrite it to make it work.
You can also delete the line with
IF @@ROWCOUNTand leave onlySELECT(...), but this of course will not prevent the pipeline form working and it will execute next activity in it, which generates costs and consume time 🙂Hello Michal,
Had some trouble figuring out what the issue is, but I am getting the below errors when I run the pipeline. Can you advice?
My set up
source Data source name destination data set
oracle db ORA
Azure SQL AzureSQL_DB AzureSQL_DB
I am trying to copy from Oracle database to Azure sql database
I have the tables ready both in Oracle and Azure sql database including the config table.
Error messages
on the GET MAX ORA
{
“errorCode”: “2100”,
“message”: “Failure happened on ‘Source’ side. ErrorCode=UserErrorOdbcOperationFailed,’Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ERROR [42S02] [Microsoft][ODBC Oracle Wire Protocol driver][Oracle]ORA-00942: table or view does not exist,Source=Microsoft.DataTransfer.ClientLibrary.Odbc.OdbcConnector,”Type=System.Data.Odbc.OdbcException,Message=ERROR [42S02] [Microsoft][ODBC Oracle Wire Protocol driver][Oracle]ORA-00942: table or view does not exist,Source=msora28.dll,'”,
“failureType”: “UserError”,
“target”: “GET MAX ORA”,
“details”: []
}
on FOR EACH ORA
{
“errorCode”: “ActionFailed”,
“message”: “Activity failed because an inner activity failed”,
“failureType”: “UserError”,
“target”: “FOR EACH ORA”,
“details”: “”
}
cource code:
{
“name”: “Goa_Incremental_Load”,
“properties”: {
“activities”: [
{
“name”: “GET CFG”,
“type”: “Lookup”,
“dependsOn”: [],
“policy”: {
“timeout”: “7.00:00:00”,
“retry”: 0,
“retryIntervalInSeconds”: 30,
“secureOutput”: false,
“secureInput”: false
},
“userProperties”: [],
“typeProperties”: {
“source”: {
“type”: “AzureSqlSource”,
“sqlReaderQuery”: {
“value”: “SELECT * from @{pipeline().parameters.ConfigTable}\nIF @@ROWCOUNT = 0 THROW 50000,’No rows in configuration table!’,1”,
“type”: “Expression”
},
“queryTimeout”: “02:00:00”
},
“dataset”: {
“referenceName”: “AzureSQL_DB”,
“type”: “DatasetReference”,
“parameters”: {
“TableName”: “Dummy”
}
},
“firstRowOnly”: false
}
},
{
“name”: “ORA CFG”,
“type”: “Filter”,
“dependsOn”: [
{
“activity”: “GET CFG”,
“dependencyConditions”: [
“Succeeded”
]
}
],
“userProperties”: [],
“typeProperties”: {
“items”: {
“value”: “@activity(‘GET CFG’).output.value “,
“type”: “Expression”
},
“condition”: {
“value”: “@equals(item().SRC_name,’ORA’)”,
“type”: “Expression”
}
}
},
{
“name”: “AZURE SQL CFG”,
“type”: “Filter”,
“dependsOn”: [
{
“activity”: “GET CFG”,
“dependencyConditions”: [
“Succeeded”
]
}
],
“userProperties”: [],
“typeProperties”: {
“items”: {
“value”: “@activity(‘GET CFG’).output.value “,
“type”: “Expression”
},
“condition”: {
“value”: “@equals(item().SRC_name,’AzureSQL_DB’)”,
“type”: “Expression”
}
}
},
{
“name”: “FOR EACH ORA”,
“type”: “ForEach”,
“dependsOn”: [
{
“activity”: “ORA CFG”,
“dependencyConditions”: [
“Succeeded”
]
}
],
“userProperties”: [],
“typeProperties”: {
“items”: {
“value”: “@activity(‘ORA CFG’).output.value”,
“type”: “Expression”
},
“activities”: [
{
“name”: “GET MAX ORA”,
“type”: “Lookup”,
“dependsOn”: [],
“policy”: {
“timeout”: “7.00:00:00”,
“retry”: 0,
“retryIntervalInSeconds”: 30,
“secureOutput”: false,
“secureInput”: false
},
“userProperties”: [],
“typeProperties”: {
“source”: {
“type”: “OracleSource”,
“oracleReaderQuery”: {
“value”: “SELECT MAX(@{item().WatermarkColumn}) as maxd FROM @{item().SRC_tab} “,
“type”: “Expression”
},
“partitionOption”: “None”,
“queryTimeout”: “02:00:00”
},
“dataset”: {
“referenceName”: “ORA”,
“type”: “DatasetReference”
}
}
},
{
“name”: “COPY ORA”,
“type”: “Copy”,
“dependsOn”: [
{
“activity”: “GET MAX ORA”,
“dependencyConditions”: [
“Succeeded”
]
}
],
“policy”: {
“timeout”: “7.00:00:00”,
“retry”: 0,
“retryIntervalInSeconds”: 30,
“secureOutput”: false,
“secureInput”: false
},
“userProperties”: [],
“typeProperties”: {
“source”: {
“type”: “OracleSource”,
“oracleReaderQuery”: {
“value”: “SELECT @{item().Cols} FROM @{item().SRC_tab} WHERE @{item().WatermarkColumn} > \nTO_DATE(‘@{item().WatermarkValue}’, ‘YYYY-MM-DD\”T\”HH24:MI:SS\”Z\”‘)\nAND @{item().WatermarkColumn} <= TO_DATE('@{activity('GET MAX ORA').output.firstRow.MAXD}', 'YYYY-MM-DD\"T\"HH24:MI:SS\"Z\"')",
"type": "Expression"
},
"partitionOption": "None",
"queryTimeout": "02:00:00"
},
"sink": {
"type": "AzureSqlSink",
"preCopyScript": "TRUNCATE TABLE @{item().DST_tab}",
"disableMetricsCollection": false
},
"enableStaging": false
},
"inputs": [
{
"referenceName": "ORA",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQL_DB",
"type": "DatasetReference",
"parameters": {
"TableName": {
"value": "@{item().DST_tab}",
"type": "Expression"
}
}
}
]
},
{
"name": "UPDATE WATERMARK",
"type": "SqlServerStoredProcedure",
"dependsOn": [
{
"activity": "COPY ORA",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"storedProcedureName": "[dbo].[load.usp_UpdateWatermark]",
"storedProcedureParameters": {
"id": {
"value": "@{item().id}",
"type": "Int16"
},
"NewWatermark": {
"value": "@{activity('GET MAX ORA').output.firstRow.MAXD} ",
"type": "DateTime"
}
}
},
"linkedServiceName": {
"referenceName": "AzureSqlDelta",
"type": "LinkedServiceReference"
}
}
]
}
},
{
"name": "FOR EACH AZURE SQL",
"type": "ForEach",
"dependsOn": [
{
"activity": "AZURE SQL CFG",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"items": {
"value": "@activity('AZURE SQL CFG').output.value",
"type": "Expression"
},
"activities": [
{
"name": "Wait2",
"type": "Wait",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"waitTimeInSeconds": 1
}
}
]
}
}
],
"parameters": {
"ConfigTable": {
"type": "string",
"defaultValue": "DeltaLoadConfig"
}
},
"annotations": []
}
}
Thank you so much Michal,
I am trying to use this concept for copying data from Oracle and Ms sql serves table to Azure sql db.
These table are updated and new data is added very often. Will your incremental azure process accomplish this task and copy all the new changes and updates made on the source database and update the azure sql tables?
Regards,
Hope
Hello Michal,
I want to create a global timestamp variable on pipeline and use it in my data flow sql query.
I have the below query but want to use the global variable in stead of CURRENT_TIMESTAMP
update Life_master set last_upd_dt =CURRENT_TIMESTAMP where job_id = 2
What I want is something like below
update Life_master set last_upd_dt =(@pipeline().Pipeline.timestampvariable) where job_id = 2 ??
How can I do that ?
Regards,
Hope
Hi Hope.
Well, it depends on database engine and the source for the value of global variable, but in general you can achieve that by:
1. Setting the variable at your pipeline
2. Reference it like you did but remember, the value in the variable is in a particular format. I’m not sure how did you set the global timestamp, but if it was for example a value of utcnow(), then it means that it needs to be converted to a proper string that your database will recognize. Just play with formatDateTime function to format it properly and of course be aware of differences between UTC and other timezones, it can matter in every case, lots of databases are designed to work with local timezone, not universal…